夜间模式
MySQL 学习笔记
SQL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库、表、字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语句,用来查询数据空中表的记录 |
| DCL | Data Control Language | 数据控制语句,用来创建数据库用户、控制数据库访问权限 |
DDL-数据库操作
sql
-- 查询
SHOW DATABASES;
-- 创建
CREATE DATABASE [IF NOT EXISITS] `database_name` [DEFAULT CHARSET `charset`] [COLLATE `collate`];
-- 删除
DROP DATABASE [IF EXISTS] `database_name`;
-- 使用
USE `database_name`;DDL-表操作-查询
sql
SHOW TABLES; -- 查询当前数据库所有表
SHOW CREATE TABLE `table_name`; -- 查询建表语句
DESC `table_name`; -- 查询表结构DDL-表操作-创建
sql
CREATE TABLE `table_name` (
`field_1` DATA_TYPE [COMMENT `field_1_comment`],
`field_2` DATA_TYPE [COMMENT `field_2_comment`],
...,
`field_n` DATA_TYPE [COMMENT `field_n_comment`]
) [COMMENT `table_comment`];DDL-表操作-数据类型
| 分类 | 类型 | 大小 | 描述 |
|---|---|---|---|
| 数值类型 | TINYINT | 1 byte | |
| SMALLINT | 2 bytes | ||
| MEDIUMINT | 3 bytes | ||
| INT / INTEGER | 4 bytes | ||
| BIGINT | 8 bytes | ||
| FLOAT | 4 bytes | ||
| DOUBLE | 8 bytes | ||
| 字符串类型 | CHAR | 0 ~ 255 bytes | 定长字符串 |
| VARCHAR | 0 ~ 65535 bytes | 变长字符串 | |
| TINYBLOB | 0 ~ 255 bytes | ||
| TINYTEXT | 0 ~ 255 bytes | ||
| BLOB | 0 ~ 65535 bytes | 二进制的长文本数据 | |
| TEXT | 0 ~ 65535 bytes | 长文本数据 | |
| MEDIUMBLOB | 0 ~ 16777215 bytes | ||
| MEDIUMTEXT | 0 ~ 16777215 bytes | ||
| LONGBLOB | 0 ~ 4294967295 bytes | 二进制形式的极大文本数据 | |
| LONGTEXT | 0 ~ 4294967295 bytes | 极大文本数据 |
DDL-表操作-修改
sql
-- 添加字段
ALTER TABLE `table_name` ADD `field` TYPE [COMMENT `field_comment`];
-- 修改字段类型
ALTER TABLE `table_name` MODIFY `field` TYPE;
-- 修改字段名和类型
ALTER TABLE `table_name` CHANGE `field` `new_field` TYPE [COMMENT `field_comment`];
-- 删除字段
ALTER TABLE `table_name` DROP `field`;
-- 修改表名
ALTER TABLE `table_name` RENAME TO `new_table_name`;
-- 删除表
DROP TABLE [IF EXISTS] `table_name`;
-- 删除并重建表
TRUNCATE TABLE `table_name`;DANGER
使用 TRUNCATE TABLE table_name,表中数据会被清空
DML-插入数据
sql
-- 给全部字段添加数据
INSERT INTO `table_name` VALUE(`value_1`, `value_2`, ...);
-- 给指定字段添加数据
INSERT INTO `table_name`(`field_1`, `field_2`, ...) VALUE(`value_1`, `value_2`, ...);
-- 批量添加
INSERT INTO `table_name` VALUES(`field_1`, `field_2`, ...), (`value_1`, `value_2`, ...), ...;
INSERT INTO `table_name`(`field_1`, `field_2`, ...) VALUES(`value_1`, `value_2`, ...), (`value_1`, `value_2`, ...), ...;DML-修改数据
sql
UPDATE `table_name` SET `field_1`=`value_1`, `field_2`=`value_2`, ... [WHERE ...];DML-删除数据
sql
DELETE FROM `table_name` [WHERE ...];DQL-基础查询
sql
SELECT `field_1` AS `alias_1`, `field_2` `alias_2` FROM `table_name`; -- AS可省略
SELECT * FROM `table_name`;
SELECT DISTINCT * FROM `table_name`; -- 去重DQL-条件查询
sql
SELECT `field` FROM `table_name` WHERE ...;WARNING
使用 WHERE BETWEEN a AND b 时,a 应当小于 b
DQL-聚合函数
| 函数 | 作用 |
|---|---|
| COUNT | 统计数量 |
| MAX | 最大值 |
| MIN | 最小值 |
| AVG | 平均值 |
| SUM | 求和 |
TIP
NULL 不参与聚合运算
DQL-分组查询
sql
SELECT * FROM `table_name` [WHERE ...] GROUP BY `field` [HAVING ...];
-- 例:查询 tb_user 中各地区三十岁以下用户数量大于 3 的所有地区
SELECT `address`, COUNT(*) AS `user_num`
FROM `tb_user`
WHERE `age` <= 30
GROUP BY `address`
HAVING `user_num` > 3;TIP
WHERE 与 HAVING 的区别:
- 执行时机不同:
WHERE分组前进行过滤,不满足条件的数据不参与分组;HAVING是分组后对结果进行过滤。 - 判断条件不同:
WHERE不能对聚合函数判断,而HAVING可以。
DQL-排序查询
sql
SELECT * FROM `table_name` ORDER BY `field` ASC; -- 升序,默认值
SELECT * FROM `table_name` ORDER BY `field` DESC; -- 降序
SELECT * FROM `table_name` ORDER BY `field_1` ASC, `field_2` DESC; -- 先对字段1进行升序排序,如果值相同则按字段2降序排序DQL-分页查询
sql
SELECT * FROM `table_name` LIMIT page_num - 1, page_size;DQL-执行顺序
sql
SELECT `addr`, COUNT(*) -- 4
FROM `tb_user` AS `user` -- 1
WHERE `age` BETWEEN 20 AND 40 -- 2
GROUP BY `addr` HAVING COUNT(*) >= 3 -- 3
ORDER BY COUNT(*) DESC, `addr` ASC -- 5
LIMIT 0, 10 -- 6函数-字符串
| 函数 | 功能 |
|---|---|
CONCAT(S1, S2, ..., Sn) | 字符串拼接,将 S1, S2, ..., Sn 拼接成一个字符串 |
LOWER(str) | 将字符串 str 转小写 |
UPPER(str) | 将字符串 str 转大写 |
TRIM(str) | 去掉字符串 str 首尾的空格 |
SUBSTRING(str, start, len) | 返回字符串 str 从 start 开始的 len 长度的字符子串 |
LPAD(str, n, pad) | 左填充,用字符串 pad 在 str 左边填充,直到 str 长度达到 n |
RPAD(str, n, pad) | 右填充,用字符串 pad 在 str 右边填充,直到 str 长度达到 n |
函数-数值
| 函数 | 功能 |
|---|---|
CEIL(x) | 向上取整 |
FLOOR(x) | 向下取整 |
MOD(x, y) | 返回 x / y 的模 |
RAND() | 返回 0 ~ 1 内的随机数 |
ROUND(x, y) | 返回 x 的四舍五入值,保留 y 位小数 |
函数-流程
| 函数 | 功能 |
|---|---|
IF(expr1, expr2, expr3) | 如果 expr1 = TRUE,则返回 expr2,否则返回 expr3 |
IFNULL(expr1, expr2) | 如果 expr1 IS NOT NULL,则返回 expr1,否则返回 expr2 |
CASE WHEN val THEN res ELSE default END | 如果 val = TRUE,则返回 res,否则返回 default |
CASE t WHEN val THEN res ELSE default END | 如果 t = val,则返回 res,否则返回 default |
约束
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 字段值不能为 NULL | NOT NULL |
| 唯一约束 | 保证该字段的所有值都是不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,非空且唯一 | PRIMART KEY |
| 默认约束 | 插入数据时如未指定该字段值,则采用默认值 | DEFAULT |
| 检查约束 | 保证字段值满足条件 (MySQL8新特性) | CHECK |
多表查询-内连接
sql
-- 隐式内连接
SELECT ... FROM `table_1`, `table_2` WHERE ...;
-- 显式内连接
SELECT ... FROM `table_1` [INNER] JOIN `table_2` ON ...;
-- 例:查询每一个员工的姓名和部门名称
-- 表:tb_emp, tb_dept
-- 连接条件:tb_emp.dept_id = tb_dept.id
SELECT `tb_emp`.`name`, `tb_dept`.`name` FROM `tb_emp`, `tb_dept` WHERE `tb_emp`.`dept_id` = `tb_dept`.`id`; -- 隐式
SELECT `tb_emp`.`name`, `tb_dept`.`name` FROM `tb_emp` INNER JOIN `tb_dept` ON `tb_emp`.`dept_id` = `tb_dept`.`id`; -- 显式多表查询-外连接
sql
SELECT ... FROM `table_1` LEFT OUTER JOIN `table_2` ON ...; -- 左外连接
SELECT ... FROM `table_1` RIGHT OUTER JOIN `table_2` ON ...; -- 右外连接多表查询-自连接
sql
SELECT ... FROM `table` AS `alias_1` INNER JOIN `table` AS `alias_2` ON ...;INFO
自连接可以是内连接也可以是外连接。
多表查询-联合查询
sql
SELECT ... FROM `table_1`
UNION [ALL]
SELECT ... FROM `table_2`;WARNING
联合查询的列数与字段类型必须保持一致。
TIP
UNION ALL 会把全部结果直接合并在一起,UNION 会对合并之后的数据去重。
多表查询-子查询
标量子查询
子查询结果返回的是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为 标量子查询。
常用操作符:= <> > < >= <=
列子查询
子查询结果返回的是一列,这种子查询称为 列子查询。
常用操作符:IN NOT IN ANY SOME ALL
| 操作符 | 描述 |
|---|---|
IN | 在指定集合范围之内,多选一 |
NOT IN | 不在指定集合范围之内 |
ANY | 子查询返回列表中,在一个任意满足即可 |
SOME | 与 ANY 等同,使用 SOME 的地方都可以用 ANY |
ALL | 子查询返回列表的所有值都必须满足 |
行子查询
子查询结果返回的是一行,这种子查询称为 列子查询。
常用操作符:IN NOT IN = <>
表子查询
子查询结果返回的是多行多列,这种子查询称为 表子查询。
常用操作符:IN
事务-操作
sql
-- 自动提交
SELECT @@AUTOCOMMIT; -- 查看提交方式
SET @@AUTOCOMMIT = 0; -- 关闭自动提交
SET @@AUTOCOMMIT = 1; -- 开启自动提交
-- 事务操作
BEGIN; -- 开启事务
START TRANSACTION; -- 开启事务
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务事务-四大特性
- 原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须所有数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务-并发问题
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入时,又发现这行数据存在 |
事务-隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | × | √ | √ |
| repeatable read(默认) | × | × | √ |
| serializable | × | × | × |
sql
-- 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
-- 设置事务隔离级别
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE]存储引擎
sql
SHOW ENGINES; -- 查看所有引擎
CREATE TABLE `table`(...) ENGINE=INNODB; -- 设置存储引擎| InnoDB | MyISAM |
|---|---|
| 支持事务 | 不支持事务 |
| 支持外键 | 不支持外键 |
| 支持行级锁 | 支持表级锁 |
- InnoDB:MySQL 默认的存储引擎。如果对事务、数据一致性有高要求,InnoDB 比较合适。
- MyISAM:如果以查询和插入为主,很少更新和删除,可以选用 MyISAM。例如:日志的存储。
- Memory:将数据保存再内存中,访问速度快。
实际上,绝大部分场景都是 InnoDB,另外两种都被别的 NoSQL 数据库替代了。例如:用 MangoDB 替代 MyISAM,Redis 替代 Memory。
InnoDB逻辑存储结构: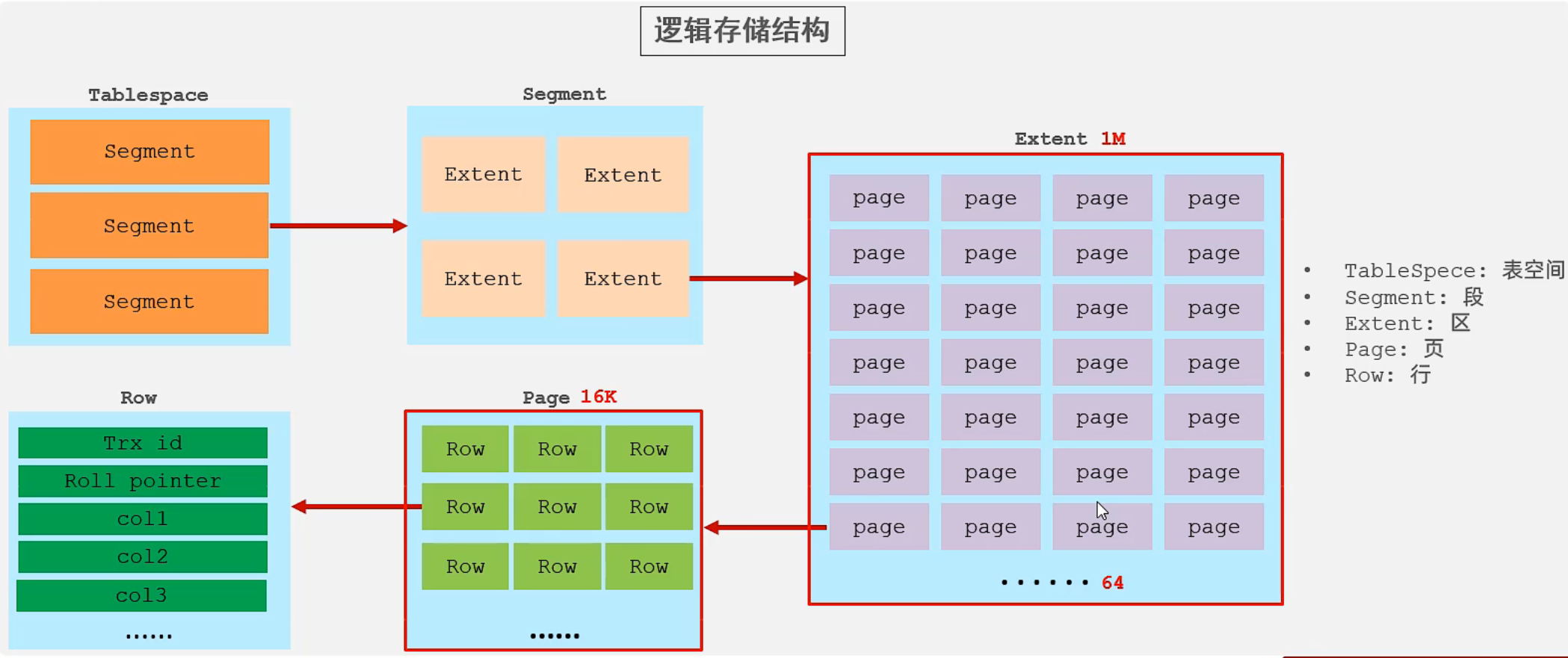
索引-分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对表中主键创建的索引 | 默认创建,只能有一个 | PRIMARY |
| 唯一索引 | 同一个表中某字段的值不重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速查找特定数据 | 可以有多个 | |
| 全文索引 | 查找的是文本中的关键字,而不是索引的值 | 可以有多个 | FULLTEXT |
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下几种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据存储和索引放到一块,索引结构的叶子节点保存了行数据 | 必须有,且只有一个 |
| 二级索引 | 将数据和索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果没有主键和合适的唯一索引,则 InnoDB 会自动生成的一个
rowid作为隐藏的聚集索引。
索引-语法
sql
-- 创建索引
CREATE [UNIQUE|FULLTEXT] INDEX `index_name` ON `table_name` (`field`, ...);
-- 查看索引
SHOW INDEX FROM `table_name`;
-- 删除索引
DROP INDEX `index_name` ON `table_name`;索引-性能分析
- SQL执行频率
通过 SHOW [SESSION|GLOBAL] STATUS 指令可以提供服务器状态信息。可在此基础上通过 LIKE 匹配出增删改查的频次信息,如:
sql
SHOW SESSION STATUS LIKE "Com_______"
-- 输出:
-- +---------------+-------+
-- | Variable_name | Value |
-- +---------------+-------+
-- | Com_binlog | 0 |
-- | Com_commit | 0 |
-- | Com_delete | 0 |
-- | Com_import | 0 |
-- | Com_insert | 0 |
-- | Com_repair | 0 |
-- | Com_revoke | 0 |
-- | Com_select | 0 |
-- | Com_signal | 0 |
-- | Com_update | 0 |
-- | Com_xa_end | 0 |
-- +---------------+-------+其中,增删改查的频次分别对应表中的 Com_insert、Com_delete、Com_update、Com_select 的值。
- 慢查询日志
sql
SELECT @@slow_query_log; -- 慢查询日志开关,0-关闭,1-开启
SELECT @@slow_query_log_file; -- 慢查询日志所在文件
SELECT @@long_query_time; -- 单位:秒。SQL执行时间超过该值就会被记入慢查询日志以上变量可以前往 MySQL 的配置文件 my.ini(Windows) / my.cnf(Linux) 进行修改:
txt
slow-query-log=1
slow_query_log_file="slow.log"
long_query_time=10- profile
SHOW PROFILES 能够帮助我们在做 SQL 优化时了解每句 SQL 的执行时间。
sql
SHOW VARIABLES LIKE "%profiling%";
-- +------------------------+-------+
-- | Variable_name | Value |
-- +------------------------+-------+
-- | have_profiling | YES | -- 当前 MySQL 是否支持 profile 操作
-- | profiling | OFF | -- 默认关闭,可以通过 SET 语句开启
-- | profiling_history_size | 15 | -- SQL 最近执行的记录数量
-- +------------------------+-------+
SET profiling=1; -- 开启 profiles 操作
SHOW PROFILES;- EXPLAIN 执行计划
EXPLAIN 或者 DESC 命令可查看 MySQL 如何执行 SQL 的信息。返回的信息如下:
txt
+----+-------------+---------+------+---------------+------+---------+------+----------+-------+
| id | select_type | table | type | possible_keys | key | key_len | rows | filtered | Extra |
+----+-------------+---------+------+---------------+------+---------+------+----------+-------+
| 1 | SIMPLE | tb_user | ALL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+---------+------+---------------+------+---------+------+----------+-------+EXPLAIN 执行计划各字段含义:
id:SELECT 查询的序列号,表示查询中执行SELECT 子句或表连接的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。select_type:表示SELECT的类型,常见的取值有:SIMPLE(简单表,即不使用子查询和表连接)、SUBQUERY(SELECT/WHERE之后包含了子查询)等。type:连接类型。性能由好到差分别为:NULL(不连接表),SYSTEM(访问系统表),const(根据主键或唯一索引访问),ref(使用非唯一索引),RANGE(使用非唯一索引,但是进行了范围匹配),INDEX(遍历整个索引树),ALL(全表扫描)。possible_keys:可能用到的索引,一个或多个。key:实际用到的索引。key_len:索引中使用的字节数,该值为最大可能长度,并非实际使用长度。该值越短越好。rows:MySQL 认为必须要查询的行数,在 InnoDB 中为估计值,并不总是准确的。filtered:返回结果的行数占读取行数的百分比,越大越好。
索引-使用规则
- 最左前缀法则
使用联合索引要遵守最左前缀法则,即从索引的最左列开始,依次生效。如果某一列不匹配,(后面的索引列无效)。
- 范围查询
联合索引中,出现 < 或 > 等范围查询,会导致后面的。
- 索引列运算
在索引列上运算将导致。
sql
-- 要求:查询手机号以166开头的用户
-- 表:tb_user, 索引:idx_user_phone(建立在phone字段上的索引)
-- 索引列发生计算,索引失效
SELECT * FROM tb_user WHERE SUBSTRING(`phone`, 1, 3) = "166";
-- 使用模糊查询代替了索引列的计算,索引生效
SELECT * FROM tb_user WHERE `phone` LIKE "166%";- 字符串不加引号
字符串类型的字段数值不加引号,。
sql
-- 表: tb_user, 字段: phone(字符串类型, 有索引)
SELECT * FROM tb_user WHERE phone = 166888; -- 索引失效
SELECT * FROM tb_user WHERE phone = "166888"; -- 索引有效- 模糊查询
尾部模糊匹配,索引有效。头部模糊匹配,。
sql
-- 表: tb_user, 字段: phone(字符串类型, 有索引)
SELECT * FROM tb_user WHERE phone LIKE "%888"; -- 索引失效
SELECT * FROM tb_user WHERE phone LIKE "166%"; -- 索引有效OR连接的条件查询
使用 OR 连接的条件,任意一侧无索引都将导致,OR 另一端的。
- 数据分布影响
如果 MySQL 评估使用索引比全表扫描更慢,则不会使用索引。
- 覆盖索引
如果联合索引的索引列覆盖了需要查找的所有字段,则MySQL不用再回表查询。
sql
CREATE INDEX idx_age_name ON tb_user (age, username); -- 建立联合索引
SELECT id, username, age FROM tb_user WHERE age = 20; -- 不需要回表查询
SELECT id, age, phone FROM tb_user WHERE age = 20; -- 需要回表查询上面SQL执行由于在二级索引上能够获取到 id, username, age,此时不再回表查询。而 phone 的数据不在二级索引上,此时MySQL会用对应的 id 回表查询拿到对应 phone 数据。
- 前缀索引
将字符串开头的一部分作为前缀建立索引。相较于将整个长字符串建立索引,前缀索引大大节省了索引空间,提高了索引效率。
sql
-- 将字段的前n个字符制作成前缀索引
CREATE INDEX `index_name` ON `table_name` (`field`(n));SQL优化-INSERT
使用批量插入代替多次的单行插入:
sql
-- 多次插入 ×
INSERT INTO tb_user VALUE (1, "Tom");
INSERT INTO tb_user VALUE (2, "Jerry");
-- 批量插入 √
INSERT INTO tb_user VALUES (1, "Tom"), (2, "Jerry");手动提交事务,代替自动提交事务:
sql
-- 自动提交 ×
INSERT INTO tb_user VALUE (1, "Tom");
INSERT INTO tb_user VALUE (2, "Jerry");
-- 手动提交 ×
START TRANSACTION;
INSERT INTO tb_user VALUE (1, "Tom");
INSERT INTO tb_user VALUE (2, "Jerry");
COMMIT;SQL优化-主键
- 满足业务需求的情况下,尽量降低主键的长度。因为每一个二级索引下的叶子节点都挂着主键。
- 插入数据时,尽量顺序插入,选择使用
AUTO_INCREMENT自增主键。因为主键无序插入可能会导致页分裂。
SQL优化-ORDER BY
Using filesort: 读取满足条件的数据行,然后在排序缓冲区中完成排序操作。所有不是通过索引返回的排序都叫FileSort排序。Using index: 通过扫描索引直接返回有序数据,不需要额外排序,效率高。
SQL优化-COUNT
SQL
SELECT COUNT(*) FROM tb_user;MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 COUNT(*) 查询全表总行数的时候可以直接返回这个数。
InnoDB 则会把数据一行一行读出来,累积计数。
COUNT 几种用法的区别:
COUNT(primary_key): InnoDB 引擎会遍历整个表,把每一行的主键值取出来,返回给服务层。服务层拿到主键后,直接按行进行计数。COUNT(field):
- 如果没有
NOT NULL约束,InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断值是否为NULL,不为NULL则计数 + 1; - 如果有
NOT NULL约束,InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行计数。
COUNT(1): InnoDB 引擎遍历整张表,但不取数据。服务层对应每一行,放一个数字 1 进去,直接按行进行计数。COUNT(0)、COUNT(-1)也是一样的效果,只要不是COUNT(NULL)就行。COUNT(*): InnoDB 引擎不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行计数。
效率:COUNT(field) < COUNT(primary_key) < COUNT(1) ≈ COUNT(*)
SQL优化-UPDATE
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。UPDATE 时尽量把索引字段作为 WHERE 条件,并且该索引不能失效,否则会从行锁升级为表锁。
锁
- 全局锁:锁定数据库中所有表
- 表级锁:每次操作锁住整张表
- 行级锁:每次操作锁住对应行
全局锁
全局锁对整个数据库实例加锁,加锁后整个实例就处于只读的状态,后续的写入操作都将被阻塞。
最典型的使用场景就是做全库的逻辑备份,对所有表进行锁定,从而获取一致性视图,保证数据的完整性。
SQL
FLUSH TABLES WITH READ LOCK; -- 锁定所有数据库
UNLOCK TABLES; -- 解锁SHELL
mysqldump -uroot -p123456 db_test > test.sql; # 备份 db_test 的所有数据到 test.sql数据库中加全局锁,是一个比较重的操作,存在以下问题:
- 如果在主库上备份,那么在备份期间都不能执行写入操作,业务基本停摆
- 如果在从库上备份,那么在备份期间从库都不能执行主库同步过来的二进制日志(binlog),会导致主从延迟
在 InnoDB 引擎中,我们可以在备份时加上参数 --single-transaction 来完成不加锁的一致性数据备份。
SHELL
mysqldump --single-transaction -uroot -p123456 db_test > test.sql;表级锁
表级锁,每次操作锁住整张表。锁定粒度较大,发生锁冲突的概率高,并发度低。应用在 MyISAM、InnoDB 等存储引擎中。
表级锁可分为三类:表锁、元数据锁(meta data lock, MDL)、意向锁
表级锁-表锁
表锁可分为两类:
- 表共享读锁(read lock):当前客户端只能读不能写,其他客户端也只能读不能写
- 表独占写锁(write lock):当前客户端能读能写,其他客户端不能读不能写
SQL
LOCK TABLES `tb_test` READ/WRITE; -- 加锁
UNLOCK TABLES; -- 释放锁,断开客户端连接也能释放行级锁
行级锁,每次操作锁住对应的行数据。锁定粒度小,发生锁冲突的概率低。
行级锁可分为三类:
- 行锁(Record Lock):锁定单个行记录的锁。行锁又分为:共享锁(S)、排他锁(X)。
- 间隙锁(Gap Lock):锁定记录间隙(不含该记录),确保记录间隙不变,避免其他事务在这个间隙插入数据,防止产生幻读。
- 临键锁(Next-Key Lock):行锁和间隙锁的组合,同时锁住行数据,并锁住前面的间隙。